| Autor | Zpráva | ||
|---|---|---|---|
| Kcko Profil |
#1 · Zasláno: 13. 5. 2023, 08:55:03
Našel jsem moc pěkný blog, kde se do podrobna rozebírají advanced věci i starší, ale třeba složitější funkce a postupy.
learnsql.com Jen tak ze zajímavosti jsem si přečetl rozbor funkce COUNT a zaujalo mě následující: - learnsql.com/blog/sql-count-function - learnsql.com/blog/difference-between-count-distinct Autor tvrdí, že následující příkazy jsou ekvivalentní a je jen pohádka, že si někdo myslel něco jiného (i já) SELECT COUNT(*) -- známá věc
SELECT COUNT(1) -- méně známá, používám a žil jsem v domnění, že to bude o fous rychlejší|
SELECT COUNT(-50) -- totální blbost, ale je to stejné jako předchozí
SELECT COUNT('cussssss jak se mas') -- totalni blbost, ale opět stejnéNo budiž, budu tomu věřit, možná se COUNT(1) týkal starších verzí MYSQL. Ale co mě zaujalo víc: SELECT COUNT(CASE WHEN order_price > 1000 THEN 1 END) AS significant_orders FROM orders; V této ukázce, přesunul filtrování přímo do COUNT funkce, já bych to dal do WHERE
Zkusil jsem si na to svojí DB a výsledkem je 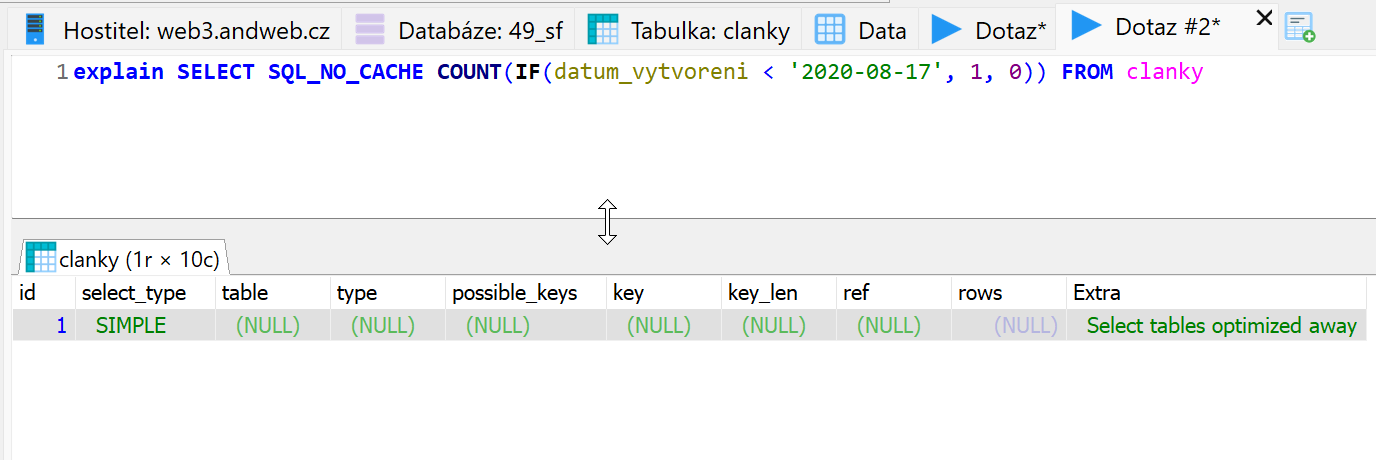
vs 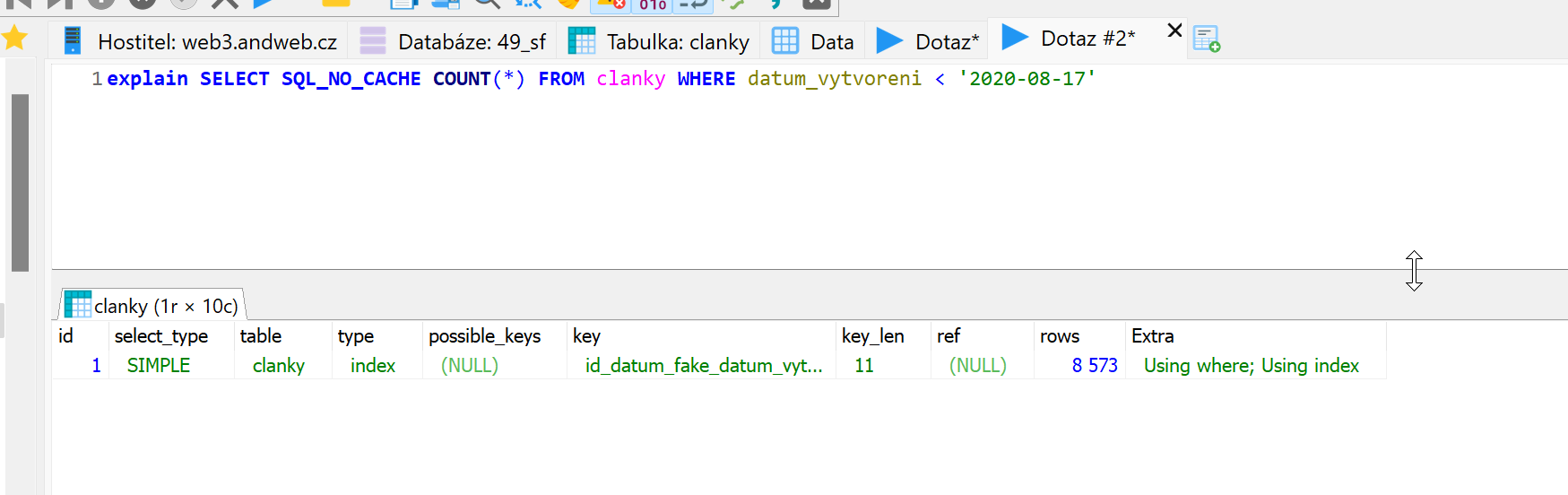
Co je zajímavé? Nepoužije se index ani v 1 případě, i když na sloupci je (takže bych to čekal) a v extra popisu je SELECTED OPTIMIZED AWAY což podle vysvětlení je to nejlepší a lepší už to nejde (tj. rychlejší než když to strčím do WHERE) Používate to tak? Co si o tom myslíte? @Kajman? ;-) |
||
| tttttt Profil * |
#2 · Zasláno: 13. 5. 2023, 12:03:33
Myslím si, že si myslíš, že ty dva dotazy dávají stejný výsledek.
MariaDB [test]> select SQL_NO_CACHE count(*) from tt where val > 50000; +----------+ | count(*) | +----------+ | 713945 | +----------+ 1 row in set (0.098 sec) MariaDB [test]> select SQL_NO_CACHE count(if( val > 50000, 1, 0)) from tt; +-------------------------------+ | count(if( val > 50000, 1, 0)) | +-------------------------------+ | 1428868 | +-------------------------------+ 1 row in set (0.201 sec) A ten explain dostávám také jiný MariaDB [test]> explain select count(if( val > 50000, 1, 0)) from tt; +------+-------------+-------+-------+---------------+-------+---------+------+---------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+-------+---------+------+---------+-------------+ | 1 | SIMPLE | tt | index | NULL | idxtt | 5 | NULL | 1426920 | Using index | +------+-------------+-------+-------+---------------+-------+---------+------+---------+-------------+ 1 row in set (0.000 sec) mysql Ver 15.1 Distrib 10.11.2-MariaDB, for Linux (x86_64) using readline 5.1 Může to být o verzích databáze. COUNT(CASE …) a COUNT(if( val > 50000, 1, 0)) není ekvivalentní. Ten IF vždy vrací non-null, takže dělá to samé jako COUNT(1). Nejspíš jsi tam chtěl mít SUM. Pokud MySQL dokáže COUNT v konstantím čase, pak nepotřebuje číst tabulku a ten explain dává smysl. Přijde mi to podezřelé, většinou je potřeba kvůli transakcím koukat do dat. Ale MySQL už nějakou dobu nesleduju.
|
||
| Kajman Profil |
#3 · Zasláno: 13. 5. 2023, 17:25:07
Kcko:
„Nepoužije se index ani v 1 případě“ Podle názvu indexu je sloupec použitý pro filtr až na třetím místě a nelze tedy podle něj rychle hledat. Jen se může číst z indexu místo z tabulky. Pro jeden výraz count nebo sum s filtrovacím výrazem uvnitř nedávají moc smysl a pochybuji, že budou rychlejší. Spíše se to používá pro generování více sloupců najednou, pokud databáze nepodporuje PIVOT operátor. |
||
| Kcko Profil |
tttttt:
Ahoj, máš pravdu, aby to dávalo stejný výsledek musí se použít SUM (protože to je skutečný součet), COUNT spočítá všechny řádky s nenulovou hodnotou (takže i s tou nulou, takže veme celou tabulku), takže se čísla liší. takže bud takto SELECT SQL_NO_CACHE COUNT(IF(datum_vytvoreni < '2020-08-17', 1, NULL)) FROM clanky SELECT SQL_NO_CACHE COUNT(CASE WHEN datum_vytvoreni < '2020-08-17' THEN 1 ELSE NULL END) FROM clanky pak to počítá korektně jako count(*) s WHERE
Kajman: Pořádně sem si to vyzkoušel (dopoledne sem to zkoušel na MySQL 5.6 a ted na Maria DB) a count ve where je znatelně rychlejší než filtrovací výraz v COUNT/SUM 0,002s vs 0,036 EDIT pustil sem to asi 20x za sebou a ty časy jsou pořád ~ 0,015s (v obou případech) Co je prosím PIVOT operátor? |
||
| Kajman Profil |
#5 · Zasláno: 15. 5. 2023, 09:46:53
Když zkusím dotaz s count case na innodb tabulce s dvěma miliony řádků, tak trvá bez ohledu na hranici kolem 0,7 s. Při použití ve where se rychlost pohybuje mezi 0,001 až 0,6 s podle toho, kolik hranice omezí řádků (tedy ve where se použije částečně index).
A ten PIVOT zjednodušuje psaní sum case a podobných kombinací přehlednější syntaxí - bez podpory learnsql.com/blog/useful-sql-patterns-pivoting - s podporou www.oracle.com/technical-resources/articles/database/sql-11g-pivot.html learn.microsoft.com/en-us/sql/t-sql/queries/from-using-pivot-and-unpivot |
||
| Kcko Profil |
#6 · Zasláno: 15. 5. 2023, 15:04:30
Kajman:
Jo tak, vím co je pivotní tabulka a marně jsem hledal v mysql co je to Pivot operátor ;). |
||
|
Časová prodleva: 12 měsíců
|
|||
0